I currently host silverbullet via Docker on a Synology Nas and I connect via https over a reverse proxy.
I face the issue that I want to write stuff in Client Mode and constantly getting my written stuff deleted with a message “Page changed elswhere. Reloading”.
What is the issue on this and why is it happening?
I checked that no other service is accessing the data.
When you say Client mode, do you mean Sync mode? Can you have a look in your browser’s JavaScript console? There should be some logging there with timestamps that may give a hint as to what’s going on. I think we’ve seen some people having issues with file systems that don’t reliably keep file last modified timestamps, perhaps this is what’s happening.
I’m having this issue as well, I don’t know if this has been resolved elsewhere (I see the same issue reported on GitHub) but I’m also using a Synology NAS as storage (btrfs) and have the problem that newly input text often disappears as supposed changes are detected elsewhere and the page reloads. Here’s some sample output:
Saving page new client.ts:667:20
Detected file change new.md 1731409384333 1731409385369 evented_space_primitives.ts:87:18
Page changed elsewhere, reloading. Old hash 1731409384333 new hash 1731409385369 client.ts:596:18
Last save timestamp 1731409384305 now 1731409401235 client.ts:602:18
Reloading page client.ts:967:12
If it is related to last modified timestamps, any idea what I can try?
So what SilverBullet does when you make a change (with a ~2s delay):
Write the file to disk
Once saved, read the last modified date from disk
Serve this back to the client
The client then polls every 5s or so to see if the last modified timestamp has changed (it doesn’t care about order) on disk and if so, reloads. This is what you’re seeing here.
What seems to be the issue is that your “old time stamp” (presumably the timestamp SB got back when you saved the file) happened AFTER your last poll result (roughly 17 seconds if my math is right, the timestamps are in ms since 1/1/1970).
I can see two reasons for this:
There’s some sort of race condition, but that would mean fetching or persisting takes a very long time (multiple seconds), I can’t really immediately explain this outcome, but we’ve seen more reports of people running into issues with slow NASes (or very large spaces)
You have two sources of truth, or some sort of “eventual consistency” thing going on at the filesystem level where at different requests, different last modified timestamps are served.
So two questions:
Are you running SB directly on the Synology, or on some machine attached to it? If the latter, perhaps try to use a local (non NAS) filesystem instead and see if that changes things (likely it will).
How many files do you have in your space, is it very large?
Thanks for the explanation - I did a few tests, with both the server and the NAS it works fine if the storage is local, as expected I guess. But I have also realised that if the NAS volume is mounted as NFS instead of SMB then it also works with no issue… I probably won’t investigate further, NFS brings some other minor problems for me with the NAS but it’s a good enough solution for now.
In answer to your two questions: the NAS is not slow and the space is very small so I’m sure that’s not it
Oh if you mounted it via smb before that may also be the issue. I’m no expert on that protocol and its handling of timestamps, but I wouldn’t be surprised if issues can originate from that.
I’m new to Silverbullet, but I’m really liking it so far!
I’m seeing the issue as well. Having read the above discussion now, I’ll see if I can pin down the issue, at least on my side. It’s hard to reproduce, but it does need to be addressed as it can cause silent data loss by subtly reverting changes that were made in the past few seconds.
I imagine it’s during the next polling interval when that happens. Where in the code does the above (i.e. write file, read last modified) happen? I’d take a look at the file I/O API semantics to see what and how it’s specifically reading the last modified stamp. I’m using ZFS and, if I’m not mistaken off the top of my head, there can be a last modified for contents and then last modified for file metadata as well.
On a separate but related note, is there an existing discussion on using WebSocket or even SSE before falling back to polling? It would probably help with this issue too since a change notification can be pushed from the server immediately on file modification. Yet another option would be a CRDT for converging changes.
Though I’m guessing those would be longer-term changes.
It seems that, at least in some cases, it’s writing the file twice in a row. I don’t have timestamps available at the moment (will try to log those next time), but here’s what was in my logs:
The first write + read is expected & was just a line of text that I added.
The next four lines all happened within a couple of seconds after I pasted a list of markdown links.
In order to reduce potential issues, I did have some plugs that I wanted to try out but wasn’t yet using, so I disabled those and only have treeview and outline-sidebar enabled now.
My armchair gut feeling, given that I’ve only been using Silverbullet for a couple of days now, is that it could be any of…
Race condition between the write call and the read polling. I assume they’re both completely separate from each other? That is, there’s no state shared between the write call and the read polling?
Two different timestamps as a result of the two successive writes? Read polling happening in between receipt of the two different timestamps? Not sure how exactly state tracking like that implemented client-side.
Clients get the last updated stamp of file metadata changes, but NOT the actual file content changes. Client thinks the file has been changed (which I assume is part of the separate interval read poll) and reloads it from the server at the same time (or slightly before) the content is written. This might seem like eventual consistency, but not exactly, since that would imply reading it back again gets old data. In this scenario, “last updated” could be finer-grained and include metadata changes, in which case there would be two stamps, one for metadata and then the other for the contents.
Again, I haven’t yet had the chance to look at any of the code yet, but I’m looking at the Deno file I/O API. The immediate things that come to mind are…
Writing a new temporary file and swapping it for the old one after it’s confirmed complete?
I’m assuming writes are async and not sync, but haven’t looked at the code yet to confirm.
Are the writes buffered or unbuffered? If they’re buffered, then on large enough files read polling could be happening mid-write, triggering the client to reload the file.
Anyway, sorry for the wall of text as I was just dumping my thoughts out. I’ll drop another reply if/when I get more useful diagnostic info.
Probably a different issue from the rest, but I experienced the same behavior when the server couldn’t write the changes. My server was out of space so all writes were failing.
For anyone that’s running this on ZFS, can you post here the value of the ZFS property atime? Command to get that is zfs get atime zroot/path/to/silverbullet (replace zroot/path/to/silverbullet with the path to your own dataset).
atime is “access time” and property on ZFS datasets that controls whether or not the access time is updated whenever it’s read. It shouldn’t be the source of this issue, but it could possibly be as I’m not sure about the semantics of deno file I/O API and how it reads metadata.
Haven’t had the time to look further into this yet, but just wanted to comment that as the file size increases, the chances of it happening also increases.
When adding information to a larger note, I’m careful to pause and wait every few seconds to make sure it doesn’t wipe out the last few seconds of text due to a reload.
I have also been experiencing this problem within the last few months. One file I usually edit (my todo list) is only 6kb, and yet it eats itself almost daily now. I pared all of completed items into a separate document and that is replicating the same problem.
I’m running SB via docker compose on Ubuntu. Space is ~64MB with 338 files/directories. Server processor load/memory usage is low.
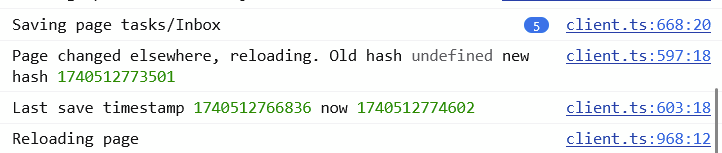
I’m seeing the following in the dev inspector:
Page changed elsewhere, reloading. Old hash **undefined** new hash 1735922082448 client.ts:597:18
Last save timestamp 1735922082411 now 1735922091794
It appears that oldHash in client.ts fails to get set. Looking at the http headers, I see the timestamps captured with the PUT actions. Could this be a cause?
While diagnosing, I found some errors related to defunct plugs. I’ve since got rid of those plugs, reset cache, reloaded system, etc. but the behavior continues.
Edit: After doing the steps in the last paragraph, the same behavior persists with the “page change elsewhere,” however, it is loading the oldHash value now.
My current leading suspicion is that it’s a race condition that involves the client-side polling mechanism. I just checked my browser console and saw something similar to what @thebarless reported.
Converted the timestamps, as printed on the browser console, to human-readable and saw that the reported inconsistency in timestamps is 4-5 seconds apart.
I haven’t yet had a chance to dig into the code yet, but if anyone can point me to where in the source the actual file writes happen, that would help me get jump-started on it sooner. Also, where the service worker code lives would help, too.
In addition, I saw @zef mention that the file is read back after it’s written. Assuming that means it’s reading the contents back, I’m curious if reading the full contents is necessary or if just reading the file metadata upon successful write would suffice.
Other potential ideas would be an issue with file sync, though that would probably have more to do with the Deno file I/O API/implementation.
Yes, I’m seeing the same as @Thebarless now. I thought I was going crazy and suspected it could have been caused by Syncthing reverting files. That would’ve been weird, because the modification dates were correct, moreover I disabled Syncthing and the problem still persisted:
client.ts:597 Page changed elsewhere, reloading. Old hash undefined new hash 1737386664925
16:24:37.350 client.ts:603 Last save timestamp 1737386664877 now 1737386677350
I’m also seeing increased CPU usage after the file is saved for about 8-10 seconds, from multiple deno run -A --unstable-kv --unstable-worker-options /silverbullet.js processes, after which the “page change elsewhere” message appears.
I’ll hop on the GitHub issue to see if I can help out there.
@aumu1 what file system are you using on your Synology? I am on btrfs and I have not noticed this issue yet. I wonder if it has to do with the file system like @zef speculates.