I’m a huge (HUGE) fan of outliners due to their ease of use. Unfortunately , Silverbullet is not one of them (but has some basic capabilities). One of my most-used features was zooming into a specific block and making it accessible next to my main page, so I could reference it easily without needing multiple windows or tabs.
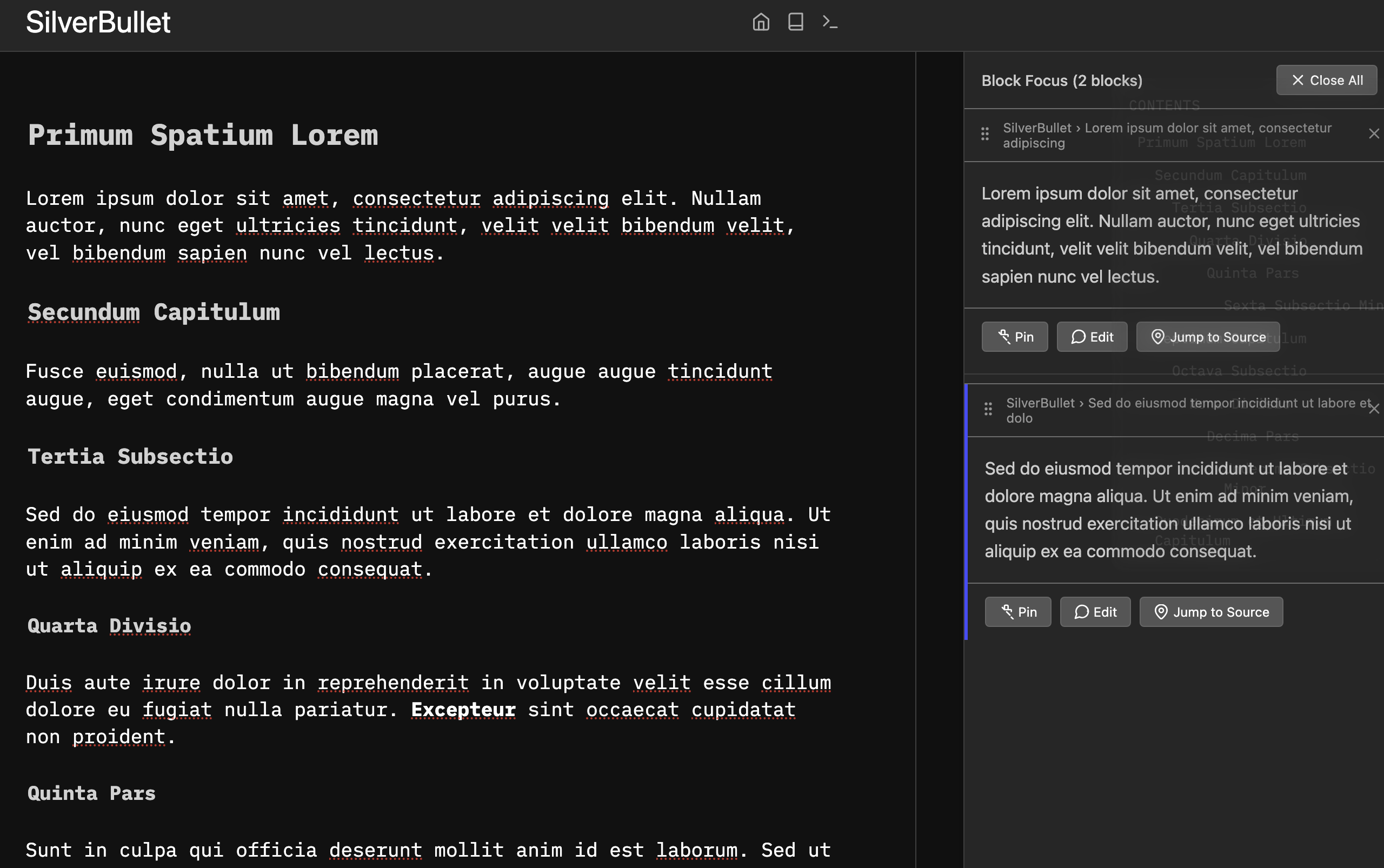
I’ve implemented a PoC of how this could look like (as a plugin). It allows zooming into different ‘blocks’ by pressing a keyboard shortcut (they are not real blocks, but delimited by e.g. paragraph, list denominator, heading), putting multiple into your sidebar and (ideally) editing them right from there (future; not yet sure if possible), pinning them (future; stored in localStorage to survive reload), reordering them (future), and jumping to the source.
Is there any interest in such a plugin, or possibly even better – is there already such a plugin?
I would love to have the possibility to create pages compound of references to (chunks of) other pages. The parts could be whole page, some section (e.g., certain 3rd level), paragraph or (the best) any custom selection. (By the way, the possibility to select some portion of a page and have it form separate object and indexed in order to further work with, e.g. refer to from other place, it is something I miss a lot.)
The compound page should allow me to edit each chunk inplace (the changes will happen in the source object) or to “transclude” them (in which case new page will be created and started it’s own life).
But, generally, yeah, I think I will also use the plug, if you create it.
Note: Now everything what’s possible (AFAIK) is to just ![[Include/Some/Page]] read-only, but only the whole page. Something more could be quite easily achieved in Lua but won’t be very “natural” to work with (something like ${showPart('/some/page', ... selected MD AST nodes ... )} and will still be read-only and highly non-ergonomic).
100% agree with you, but unfortunately this is going to be near impossible with how Silverbullet has been built. There is no real concept of blocks (besides the semi-blocks via -). Blocks come with many considerations, especially regarding performance, and this might be the reason we don’t have them (only @zef might know).
While you can reference individual sections of a page by location, this is non-static and will change if you add/remove text from your page.
The only way I’ve found around it, is to ‘intelligently’ determine sections by AST and other markers like you said, e.g. “anything between headings”, “anything part of a semi-block”, “a paragraph”. This works okay-ish but never as reliable as a true block-based app.
In addition, editing of those sections becomes very challenging, as you cannot simply reference a block and update it. You’d have to search for the string you extracted in the original page and try to replace it.
Apps like Looksyk took a different approach – they are fully block-based and put the whole space into memory, which in today’s times of high RAM availability might be a very smart move. This allows block usage with high performance and avoids the issues of file-based access.
Silverbullet has no “blocks” (which can be very different things depending on who you ask), because markdown has no “blocks”. A block style editor is vastly different from a plain markdown editor and first and foremost is not as easy to store in plain text files, because as I already pointed out, markdown has no “blocks” and alternative formats or extensions are mostly proprietary, killing the whole idea of using a ubiquitous format like markdown. This is the #1 reason Silverbullet doesn’t have blocks (Correct me if I’m wrong @zef).
Maybe I’m missing something, but I don’t see how performance plays into any of this. If anything, they are probably better for performance, because you only “lazy load” blocks much more easily.
One implementation, i can think of, would be to “smartly” determine the block when the user “zooms” into that block and just add a tag and the beginning and end of that block (Something like #block-start-h235b2, #block-end-h235b2). This way you can always keep track of that block. Editing is easily handled. The user has direct control over everything, etc. Could hide the tags using css.
Are you sure they put the whole space in ram? I know people who have tens of gigabytes in there space from pdfs/images etc., this would be insane. This especially seems like an unnecessary move, because the app would have to load big spaces (even less than a gigabyte) into ram, which takes considerable time, for a user to edit a single page and leave. (Whole discussion we had when online mode got removed and people wanted to edit on remote devices and had to load the whole space.) And it’s not like SSDs are slow. The whole thing is in your indexedDB on your disk, rendering the DOM takes longer than loading that text from the disk. I don’t see how that should be a bottleneck, but I already stated that above.
Pretty sure it is just the Markdown content that is being put into RAM, not binary files as there’s no real reason to keep them in memory.
Block performance overhead imo comes from bidirectional sync (update a block, all references to it need to be updated), ideally not polluting the Markdown with block references (see Logseq which has relatively clean Markdown files except for documenting collapsed blocks) but keeping it in metadata files or databases, depending on the implementation management of nodes in a graph incl. parent/child blocks, queries working against individual blocks etc.
Despite added complexity blocks provide the best user experience (in my humble opinion) due to their flexibility, features such as zooming, collapsing, indentation, embedding blocks elsewhere, editing blocks from multiple places while keeping current context, easily jumping to parent blocks via breadcrumbs, quickly moving a block including related content etc. For example, when preparing for a specific task I often need to reference 10+ of my previous notes, being able to have each exact reference rather than full pages all on the same screen is invaluable for quick reference or edits.
Temporary tags to make specific sections referenceable and editable sounds like an interesting idea!
Do you have a source for the performance issues, because I can’t quite seem to follow?
Logseq uses a completely proprietary format, which is baked to markdown only when exported? Logseq is not a markdown editor. It can just by “coincidence” export to markdown.
Maybe we mean the same thing – Logseq stores notes in plain markdown files, with some custom properties, by default (at least until recently, now there’s also a database option). It’s fundamentally a markdown-based app, not just when exporting.
Updating references in context of:
Block A
{{embed Block B)
Block B ← change this, now embedding reference needs to be updated in real-time
Got it – then its just terminology. It is proprietary in the sense that there are additional meta tags being added, though it is still mostly Markdown aka text files with Markdown formatting and Logseq specifics on top. I can read them in any Markdown editor, even though the specifics (e.g. id::, {{embed}} will not be rendered properly. To be fair Logseq has no real way to export into pure Markdown – it will skip its metadata but other proprietary tags like admonitions will remain.
id properties are not added to every block, just when being referenced.
There will be a performance impact as you have to parse and render this proprietary Markdown into individual blocks (indicated by -) or manage real-time updates across all references (e.g. having the same reference five times on the current screen requires five updates or rerenders). That’s why there is lazy loading of blocks, for example. This is one of the main reasons stated by the Logseq devs for moving to a database-driven format.
Created a first working PoC of editable zoomed blocks. It is ‘working’ in concept, despite the Frankenstein code, but clearly very buggy. Might not be the best approach either, but it doesn’t require a tag/modification of Markdown.
Approach:
Focus a block and record the position (block start/end)
Editing a block uses this position.
If main page (main panel) is edited and block position is shifted, the side panel is synced (checking for changes every 5 seconds)
If when editing the content at location doesn’t match what’s currently in side panel, I look to see if it has been moved to the next 100 chars (arbitrary) and update if found again