I’m running v2 on docker, and I update about once a month. This quite often requires several “refresh” hits on every device, and eventually a full re-index seems to happen. This is especially painful on the phone, taking multiple minutes.
Are you sure it always does a full reindex. On some updates something called the desiredIndexVersion has to be bumped, because internally some things about indexing changed, which require a completely new index. This isn’t done on every “update” though, but it was done on the last one.
So, not always, but pretty painful when it does occur - it takes some time for a visual indicator to even appear, and the indexing time seems unexpectedly long (even on a PC) - this is why I refresh multiple times, I’m not 100% sure that’s necessary. While it’s not strictly “blocking”, the nature of my space is such that it’s unusable during a full reindex, as my main page has functions that seem to be loaded last.
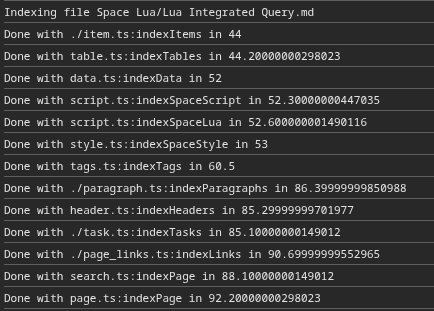
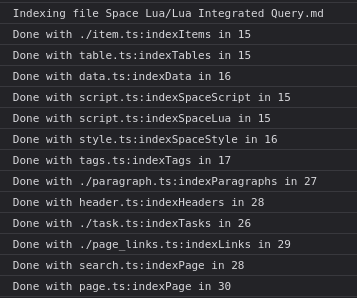
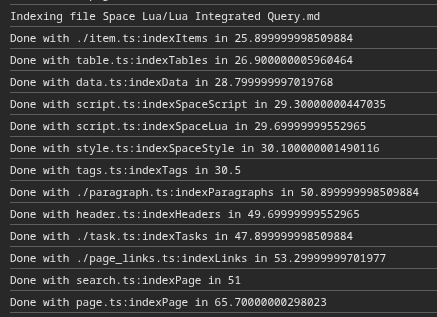
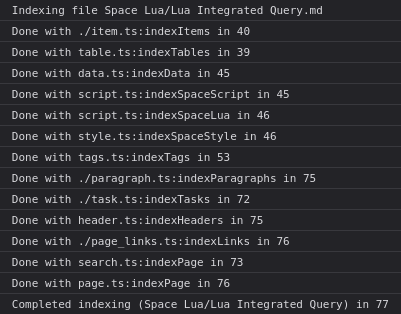
This just got me curious, so I did some very rudimentary benchmark. And I haven’t found any big outliers in the index functions, but there seems to be a massive difference between chromium and firefox waterfox. I was always of the assumption that chromium is much more optimized. Maybe it’s just my benchmarking setup, unsure. (Time is in ms, Firefox seems to do some finger printing protection and doesn’t provide floats).
Also, something I noticed is that silversearch is pretty slow at indexing actually, but it’s not a problem, because it’s running in a different worker. Would have thought it’s quicker
Thanks for looking at this! I’m also using silversearch, and I figured it’s in parallel (indeed that’s not “blocking” for using the space). Would you care to share a patch for the timing logging so that I can check it out myself? And are you triggering just by calling the “Reindex” command?
I would not be surprised a lot of optimization can still happen here. Generally I tend to only focus on optimization once performance actually becomes a problem. Perhaps we’re reaching that stage. Next step would be to identify exactly where the time is spent.
I also noticed indexing got a lot slower since installing silversearch, which is not that surprising. There’s probably solutions there too.
Some of this is optimization, some of this is surprise. A “server has updated since this client last saw it, reindex is necessary” message would go a long way.
But I feel like I got something twisted here. When I look at the time it takes to run all event listeners, I’d assume it would take at least the sum of the times it takes to run all the single functions (at least all the ones from one webworker, because afaik webworkers themselves still run single threaded), but that’s not the case. It seems to take as long as the slowest function. Weird Yep, the timings are not supper correct, because they all sit in the message queue for the worker. So the longest one probably just sat in queue the longest.
Also the timings don’t seem to be super consistent compared to the ones above.
I can’t make much sense of what’s going on (because there are lots of “Done with” lines with smaller, per-page indexing numbers), but here are a few tidbits:
I have used the network tools to throttle to 4G speeds; this doesn’t seem to slow things down, so network doesn’t appear to be a bottleneck.
It uses 250% CPU throughout, on my AMD Ryzen 5 7600 6-Core. So some concurrency is occurring.
Hitting “Space reindex” does nothing… until I navigate away from the page. If I do it twice and then navigate away, the indexing percentage starts at -99% (negative 99%)
Firefox indeed seems much faster, using 150% CPU for roughly half the time on the same machine. (Same “no reindex until navigate” issue though)
Note that a full space reindex starts with a “Clearing page index…” operation which is actually very expensive as its implemented now (maybe can optimize this), so you may think nothing is happening for a while but then things start to kick in all of a sudden.
Apparently there’s something important I missed - silversearch. My space is about 1,300 documents, 75MB, and loads in 40 seconds without silversearch, and just over 3 minutes with silversearch. That’s on my reasonably-powerful desktop; my phone is where it really hurts (there it takes about 3 minutes without silversearch, and about 10 with it). Furthermore, if I disable indexing altogether by using config.set to disable index.search.enable, index.search.enabled (for good measure) and index.paragraph.all - it finishes in just under 10 seconds! (I’ll call this mode “no indexing whatsoever” later, though I’m confident some indexing does indeed occur)
The main issue for me is “time to index page load”. My index page is a project management “show my active and snoozed projects” query-set (which uses front-matter for snooze times), and it only shows pages that have been queried. It works just fine in the “no-indexing-whatsoever” mode; however, in the “yes-indexing” modes, I have to wait for all indexing to finish before it loads everything. I guess what I’d expect is the “no-indexing-whatsoever” stuff to load first, and then for indexing to happen in the background.
Am I alone in wanting such a pony, or would this be useful to other people?
To be precise, when a user first opens any SB page that does not yet exist in their IndexedDB, the system should, whenever possible, first load all available content related to the current page, and only then proceed to fetch other pages and their indexes ?
A website, like a person, makes its strongest impression at first sight.
We should not let the indexing mechanism make SB appear any less immediate or engaging than other “instantly responsive” personal sites.
apart from SB’s own indexing mechanism, there are also certain CDN-related factors involved — it’s not entirely SB’s fault, as the deployment environment of each individual plays a significant role as well.
Thanks for this input, it’s helpful. I’ve felt unhappy with the time it takes to get SilverBullet into a workable state with an initial sync/index. My own space is also approaching about 2000 pages now and every reindex phase indeed takes a painful amount of time as well. Sync usually is actually surprisingly fast, but then the indexing…
Based on the ideas here I think a path forward could indeed be to have a mechanism to do indexing in a phased way. Such phases could be:
Initial: index page objects, with tags and frontmatter + space lua. Page objects are the most heavily used (also by SilverBullet itself, e.g. to pupulate the page, meta and document picker) so getting data for that first would be good. Extracting space lua scripts as well (cheap to do) would allow basically switching on all Space Lua powered functionality and configuration after this phase.
Deep: this is where the rest of the indexers could run indexing items, tasks, paragraphs, full text search (Silversearch etc) etc.
Perhaps more phases are useful. I feel that things like full text search could happen at a more leasurely pace (it also takes a lot of CPU power now), but I think even splitting these two phases out could make SB usable significantly faster.
Still have to think how to do this, perhaps by splitting the page:index event into separate ones per phase
I think it’d help to have a separate “download” phase too; currently it seems that the order is “fetch a page, index it, fetch the next page”; if we instead had a “download everything” phase at the start, we could accomplish the indexing later even if the connection dropped out (I’ve been trying to use silverbullet on an airplane…)
Having the download phase be separate also allows us to do things like concatenate (or even zip) all of the files together, which would cut back on a lot of TCP overhead.
As of 2.1 (or 2.0, not sure) not really, the sync engine and indexer operate separately. The sync engine performs purely sync actions even in parallel without waiting for anything, the indexer is a separate process (literally, since it runs in the main thread whereas the sync engines runs in the service worker) that picks up on new files being added and then schedules them to be indexed.
This is why you will likely also see the black and blue circles swap back and forth as each reports progress separately (a bit messy visually)
Ah, that’s odd. Observing Chrome Devtools, even after cutting off the network using its “throttling” feature, it seems to successfully fetch pages even when offline. I guess that’s not a true fetch. Thanks for clarifying!
I have just started silverbullet with my 5000+ markdown notes (i noticed that the index is also importing quite some '.txt' duplicates which are zim wiki syntax so that'll be 9900 files in total). all in all it's been like 20 minutes and it barely got to 57%. By reading the other comments, if this process repeats on other devices then this is a huge problem especially on mobile.
@zef , looking at the silversearch & other PLugs, can I safely conclude that all the work is being done on the frontend?
If so, in my perspective is a huge waste of resources.
I've built my own note taking app in the past and I used a sqlite database with full text search 5 for indexing which would have been fully indexed by now. Since silverbullet's 1 binary implementation i believe this could be a very viable approach for the go backend, which would solve a lot of problems and needless complexity.
Given the PWA nature.. there are workarounds to this including WASM for sqlite and sharing that database;) IF such a feature would be to have offline-first requirements. However I imagine most people might just use Silverbullet locally.
Zim Wiki uses sqlite too for the FTS indexing while keeping the flat files around on disk.
In my opinion having the backend do the work with proper concurrency instead of letting the frontend is probably the way to go. I'm open to finding the reasons out why this is actually done on the frontend.
40 minutes in it's just at 91%. which is extremely slow, it will be death on a mobile phone. I'm pretty sure there will be many people who have thousands of notes lying around, this is just one space, I wonder what would have happened if I'd put the long texts from other projects.
THe only reason I gave silverbullet a go was because of the tiny go backend as I tend to ignore most typescript similar projects due to the slowness.
I just began using SilverBullet and may probably not fully understand how it actually works under the hood. My apologies for making premature presumptions. I'm just concerned as I truly want to use it and I need to decide if investing the time and energy will be wroth it:)