I did this in v1 to create a clickable index to all my daily journals, is there an equivalent in v2?
```query
page
where name =~ /^Journal\/Day\//
render [[Custom/Journal]]
order by name desc
```
I did this in v1 to create a clickable index to all my daily journals, is there an equivalent in v2?
```query
page
where name =~ /^Journal\/Day\//
render [[Custom/Journal]]
order by name desc
```
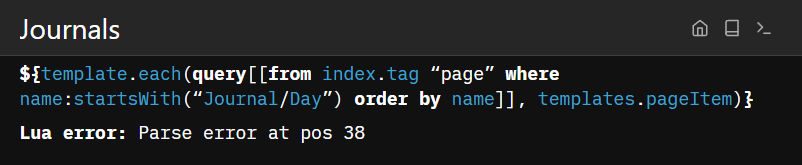
${template.each(query[[from index.tag “page” where name:startsWith(“Journal/Day”) order by name]], templates.pageItem)}
this should work, you might need to adapt it to your specifics
${template.each(query[[from index.tag “page” where name:startsWith(“Journal/Day”) order by name]], templates.pageItem)}
It doesn’t look like space-lua, where should I place it?
It is Space Lua. Those are called Lua Expressions. And the Space Lua used here are LIQ
right where you want to see your list, try it in your index page for example
the ${…} is the way to insert space-lua directives into your page/markdown
Getting an error Lua error: Parse error at pos 38
The page where I wish to show the index is /Journals, so also tried replacing index.tag with Journals.tag, same error
Try replacing the quotes with actual quotes "
red lines are fine, it’s just the browser checking the grammar
Does your Journals entries begin with exactly “Journal/Day” ?
“Journal/Day/something” or “Journal/Day_something”… etc
if by any chance “Day” is a place holder for a changing index i.e.: it changes every … day
try with name:startsWith(“Journal/”)
They begin like this
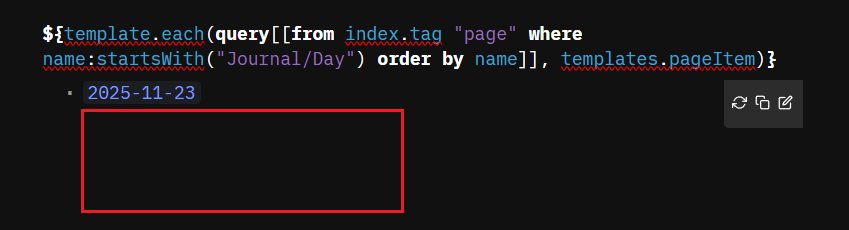
Ok thanks, there was a mismatch in the names, all fixed now, but I’m getting only the filename, how do I get the full contents of the daily journals?
I expected to see contents of 2025-11-23 in the red box
try templates.fullPageItem instead of templates.pageItem
oops misunderstood you
you want the whole content of the page ?
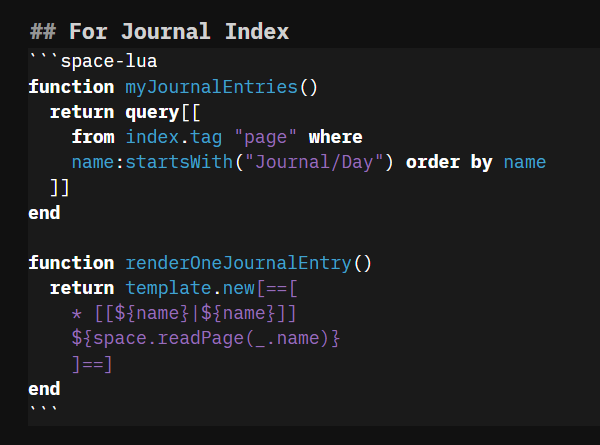
Yes, I wanted the full content of every daily journal, I use the Journals page review for patterns across all the notes without having to click around ![]()
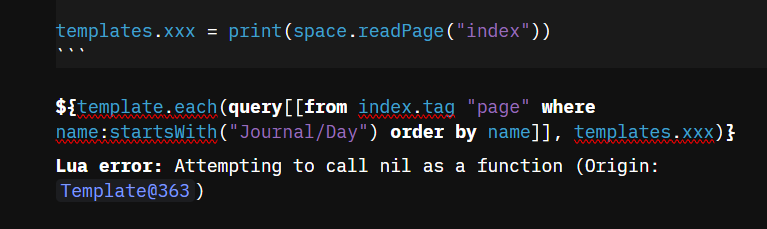
ah ok, maybe have a look at space.readPage() in the manual/API “API” should be straightforward ![]()
Actually prior to your post, I did, but I got an error and thought it was AI slop. Let me try again.